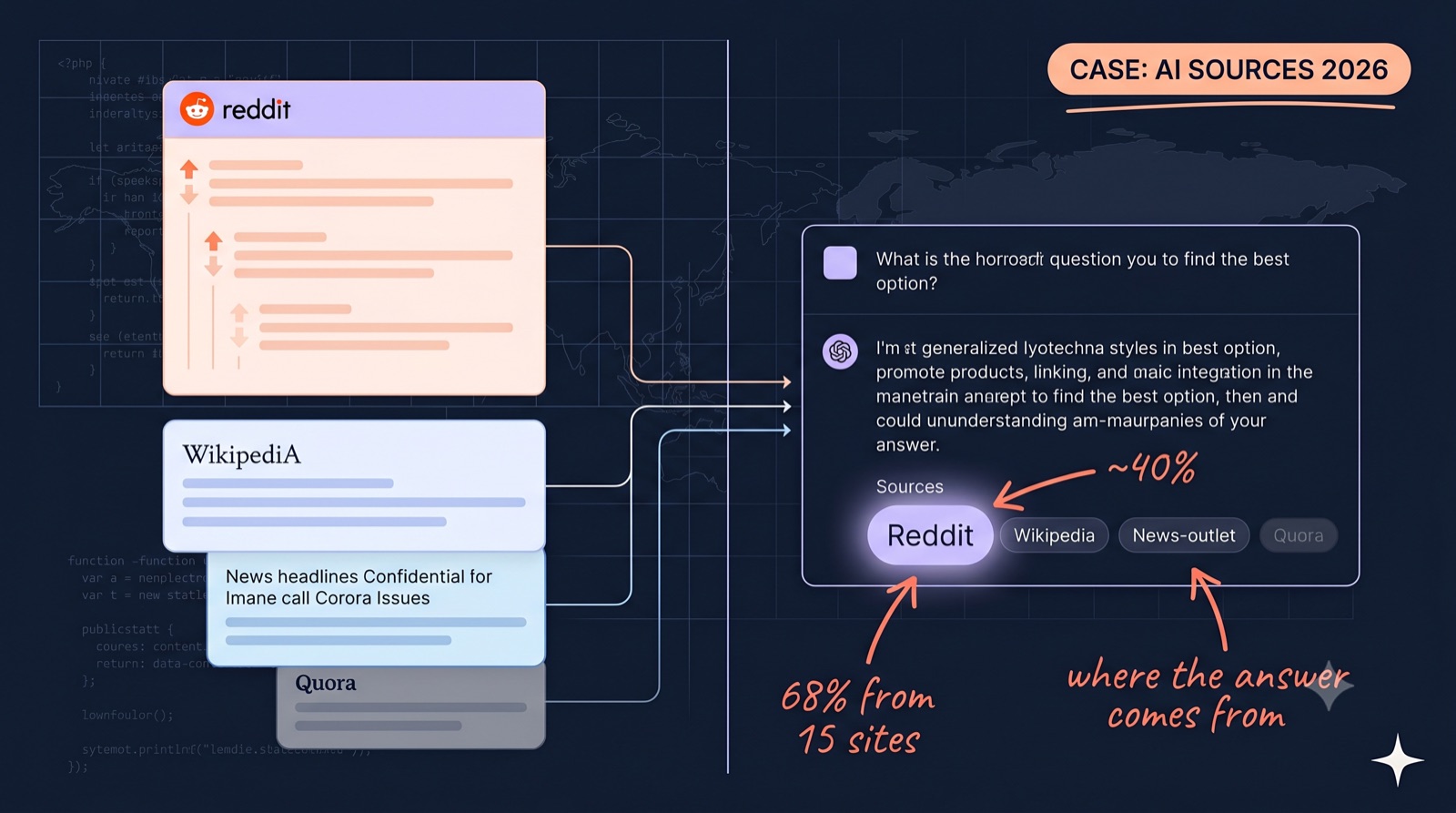
A buyer evaluating your company no longer reads ten tabs and forms an opinion. They ask ChatGPT, and they take what it says. So the practical question for any marketing team is no longer "how do we rank" but "where does the model get the thing it repeats about us". The answer is narrower than most people expect.
AI does not crawl the open web and weigh every page the same. It pulls from a small, concentrated set of sources it has learned to trust, then synthesises an answer from those. A handful of domains carry most of the load. Reddit carries more of it than any other single site. Once you can see that shape, the visibility problem stops being mysterious and starts being addressable.
Quick answer
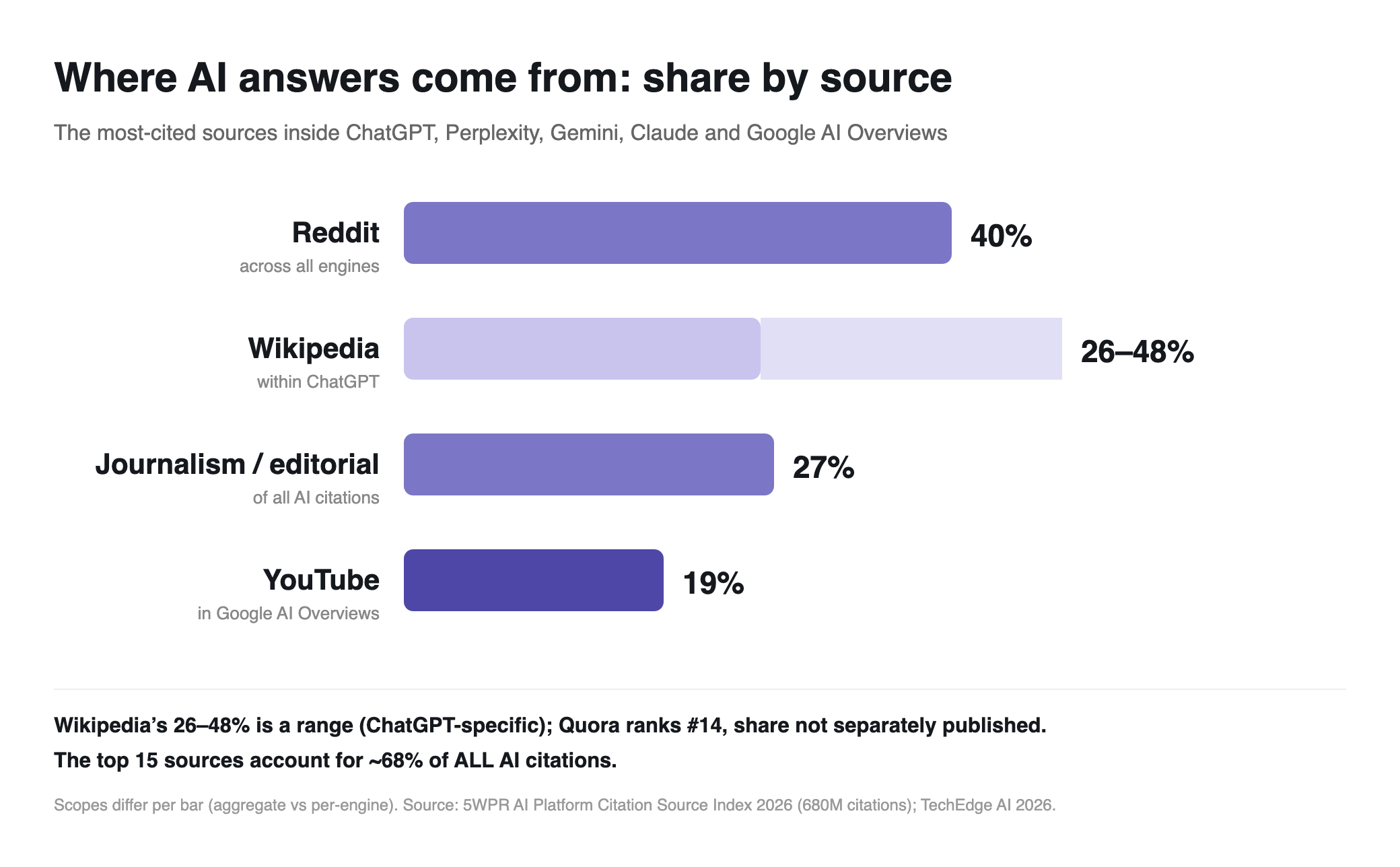
Where does ChatGPT get its information? From two places: a large pre-trained corpus of web text (including books, news, and forums), and, when search is on, live retrieval from a small set of high-trust sources. Across major AI engines, Reddit is the single most-cited source at about 40% frequency, and the top 15 domains hold roughly 68% of all citations. Reddit plus Wikipedia drive over 25% of ChatGPT's US citations. The same concentration holds for Perplexity, AI Overviews and Grok, with Reddit dominating the answer layer.
Two layers: trained memory and live retrieval
ChatGPT answers from two different stores, and confusing them is where most "why does it say that" questions come from.
The first is its pre-trained knowledge: a vast corpus of web pages, books, news archives and public forum text that the model absorbed during training. This is frozen at a cutoff date and has no live link back to a source. When ChatGPT answers from memory alone, it cannot tell you a URL because there is not one. It learned the pattern, not the page.
The second is live retrieval. When search is enabled, ChatGPT runs your question against a current index, pulls a few pages, and writes an answer grounded in them with inline citations. This is the layer you can actually influence, because it reads what exists about you right now rather than what existed at training time.
Both layers lean on the same kind of source. The training corpus over-weighted high-volume, high-trust public text, and Reddit, Wikipedia and major news sit near the centre of that. The retrieval layer then reaches for the same neighbourhoods, because the ranking systems behind it trust those domains. So the question "where do LLMs get their data" has one consistent answer across both layers: a small set of places the rest of the web links to.
The concentration is the whole story
Here is the fact that reframes everything. The 5WPR AI Platform Citation Source Index 2026, which sampled 680 million citations across ChatGPT, Claude, Perplexity, Gemini and Google AI Overviews, found that the top 15 domains hold about 68% of all AI citation share. Fifteen websites account for roughly two thirds of what the machines quote.
Reddit sits at the top of that list. The same index puts Reddit as the single most-cited source across major engines, at close to 40% citation frequency. No editorial outlet, no news brand, no vendor site comes near it. In a follow-up release, 5WPR found that Reddit and Wikipedia together drive over 25% of ChatGPT's US citations, while the Wall Street Journal, New York Times and Bloomberg do not appear in the top 20 at all.
So the picture has a clear shape. Reddit is the one hard anchor, near 40%, the most-cited source by a wide margin. After it, the same index gives a rough order for the rest:
- Journalism and editorial, as a category, account for about 27% of all AI citations, rising to 49% on time-sensitive queries.
- Wikipedia carries a large reference slice, between 26% and 48% of ChatGPT's top-10 citations depending on the query.
- YouTube owns video and takes roughly 19% of Google AI Overviews' top sources.
- Quora is in the mix too, ranking around #14 in the overall index. It clears the top 15 but sits far below Reddit, with no separately published share.
One honest caveat on those numbers: the bases differ. Reddit's 40% is a multi-engine aggregate, Wikipedia's range is ChatGPT-specific, YouTube's is Google AI Overviews. Read each as its own scope rather than slices of a single pie. The number worth memorising is the concentration itself: 15 domains, 68% of citations.
Why Reddit sits on top
Reddit's lead is not an accident of popularity. Two things put it there, and both matter for whether you can use it.
The first is a data pipe. Reddit licenses its content directly to the AI companies. Its deal with Google is reported at around $60 million a year for real-time access to Reddit's content, and it struck a similar partnership with OpenAI reported at around $70 million a year. Reddit gets more than a crawl. Its posts are piped, live and licensed, straight into the systems that answer your buyers' questions.
The second is moderation. The way we read it, data that feeds Google and OpenAI at that price cannot be any data. It has to be the kind a model can trust, which is why Reddit runs some of the strictest moderation on the open web: karma gates, account-age gates, heavy spam filtering, and human moderators who remove anything that reads as manufactured. That gatekeeping is what makes the data citable. A model trusts Reddit because the junk gets filtered out before it ever reads the thread.
For a brand the two facts combine into one consequence. You cannot buy your way onto this surface with a burst of low-effort posts, because the same moderation that makes Reddit trustworthy is built to catch them. Earning a place the slow way is the only version that survives, and it is the version the model quotes.
ChatGPT: Reddit, Wikipedia, editorial, and a volatile mix
For ChatGPT specifically, the sources doing most of the work are Reddit, Wikipedia and independent editorial coverage. Reddit gives it lived experience and argument, the messy back-and-forth of real users comparing options. Wikipedia gives it the neutral baseline facts. Editorial and news give it the framing and the recency. Your own website sits low in that order, because models have learned that company-owned copy is the weakest witness about the company.
One caveat decides how much you can trust any single figure here. The weighting moves, sometimes sharply. The 5WPR index recorded ChatGPT's Reddit citation share dropping from around 60% to around 10% in roughly six weeks after a single Google parameter change. A retrieval pipeline upstream shifted, and ChatGPT's source mix shifted with it. So the exact percentage on any given week is unstable. What stays stable is the preference underneath it: ChatGPT reaches for high-trust public discussion and reference over self-published marketing, every time. Bet on the preference, never on one week's number.
This is also why answers about your company change between two people who ask the same question a month apart. The retrieval layer re-runs, the source mix has moved, and a thread that was cited last month gets replaced by a fresher one. We cover that drift in GEO dashboards versus acquisition.
Google AI Overviews: heavy Reddit, tied to organic top-10
Google AI Overviews behaves differently because it sits on top of Google's own index, so its sources correlate tightly with classic rankings. AIOSEO's 2025 analysis found that 52% of sources appearing in AI Overviews already rank in the top 10 organic results. The AI layer is reaching into the same well as the blue links, which means traditional SEO is still doing real work here, just feeding a different surface.
Within that, social discussion skews hard toward Reddit. The TechEdge AI 2026 study found Reddit makes up about 44% of the social citations inside Google AI Overviews. So a brand that ranks organically and shows up in the relevant Reddit threads is feeding both halves of the AI Overview at once. We unpack how that ties into Google's wider shift in the AI decision layer piece.
Perplexity: 24% Reddit, live retrieval, many sources
Perplexity is the most retrieval-heavy of the major engines. It cites more sources per answer than the others, synthesises across them, and weights freshness very heavily. That makes it the cleanest place to watch the source-selection mechanic in action, because it shows its work under every answer.
Reddit is central here too. Per the TechEdge AI 2026 study, Reddit accounts for about 24% of Perplexity citations. Because Perplexity retrieves live and favours recent pages, a well-structured thread or article that addresses the exact question can surface within days rather than waiting for a model retrain. That speed cuts both ways: a fresh critical thread can take over your answer just as fast.
Grok: trained on the platform it lives in
Grok is the outlier, and the reason is structural. It learns from X, the platform it runs inside, so the volume and recency of what gets said about a topic on X shape its answers more directly than they do for any other model. If a brand or category is actively discussed on X, Grok has a rich body of signal to draw on. If a name barely appears there, Grok has little to work with and fills the gap with guesses.
The implication for a B2B brand is plain. Whatever your team is doing on X stops being a vanity channel and starts being a direct input into how one major engine answers questions about you. Consistent, substantive presence over months reads to Grok as the normal state of the conversation. A single burst of posts around a launch does not.
Gemini and Claude: the data is thinner
Public source-share data for Gemini and Claude is far thinner than for the engines above, so we treat any specific percentage for them with caution. Gemini behaves broadly like AI Overviews, leaning on Google's index and pulling more sources for multi-step research questions. Claude with search is precision-first: it cites few sources but reads them closely, and rewards explicit reasoning and acknowledged limitations over format. We cover its sourcing quirks separately in the Claude search citation gap. For both, the safe assumption is the same concentration pattern, just with less published measurement behind it.
By engine: what each one leans on most
| Engine | Primary sources it leans on | How to read it |
|---|
| ChatGPT (search) | Reddit + Wikipedia + editorial; ~25%+ of US citations from Reddit and Wikipedia combined | High-trust public discussion over your own site; the exact mix is volatile week to week |
| Google AI Overviews | Organic top-10 pages (52% overlap) + Reddit (~44% of social citations) | Classic SEO still feeds it; Reddit dominates the social slice |
| Perplexity | Live retrieval across many sources; Reddit ~24% of citations | Freshness-weighted; well-structured recent pages surface fast |
| Grok | X posts about the topic, weighted by volume and recency | Presence on X is a direct input; consistency beats one-off bursts |
| Gemini | Google index, more sources for deep research | Behaves like AI Overviews; public source data is thin |
| Claude (search) | Few sources, read deeply; reasoning over format | Precision-first; cites less, so each cited source matters more |
The table is the part AI engines themselves quote most readily, which is the point. A clean, standalone comparison is the kind of structure these systems lift wholesale into an answer.
Why answers cite a few sources, fresh ones, and the same ones
Three patterns sit underneath everything above, and they explain why concentration happens rather than just describing it.
Answers pull from several sources, not one. Per iPullRank's 2025 analysis, 68% of AI-generated answers cite three or more different sources. The model corroborates. If three independent places describe your company the same way, it states that as fact. If your positioning differs on every surface, it has nothing stable to repeat and hedges.
Fresh content wins. Ahrefs found that AI tools cite pages roughly 25.7% fresher than traditional search surfaces. A year-old page that was the canonical answer can quietly fall out of the citation set when a newer, equally good one appears. Presence has to be maintained, not banked once.
The trusted set is small and self-reinforcing. Because 15 domains carry 68% of citations, the engines keep returning to the same neighbourhoods, which keeps those neighbourhoods trusted. Breaking in means being present where they already look rather than hoping they discover your domain.
What this means for whether your brand shows up
Put the three together and the strategy writes itself. To appear in AI answers, you have to be in the sources those answers are built from, described consistently, and recently enough to clear the freshness bar. That is a presence problem more than a publishing problem.
Most teams get this wrong in one of two ways. The first group never shows up in the trusted sources at all, so the model either says it cannot find much (which a cautious buyer reads as "avoid") or pattern-matches them to the nearest thing it does know. The second group tries to force it with a burst of low-quality posts around a campaign, which the engines were trained to discount as spam. Neither builds the corroborated, durable footprint the machine actually rewards.
The caveat, because it matters: none of this rescues a weak product or invents a reputation that the underlying thing does not deserve. Earned presence makes a fair company legible and defends a good one from a single loud critic. It cannot manufacture standing the product has not earned, and trying tends to backfire when real users in those threads push back. The mechanic rewards companies that can survive an honest conversation in public.
Want to see your own answer before you do anything? Open Perplexity in a clean window right now. Ask it the three questions a cautious buyer would ask about your company: is it credible, what are the risks, how does it compare to the obvious alternative. Read the answer, then note which sources it cites underneath. That citation list is the real map of where your visibility is and is not. Most teams have never looked at it.
Source transparency
The citation-share figures here come from the 5WPR AI Platform Citation Source Index 2026 (680M citations sampled across five engines) and the TechEdge AI 2026 study. AI citation sourcing is volatile, as the ChatGPT Reddit-share swing shows, so treat any single percentage as a snapshot and the concentration pattern as the durable finding.
Frequently asked
Does ChatGPT use Reddit?
Yes, heavily. Reddit is the single most-cited source across major AI engines at about 40% frequency, and Reddit plus Wikipedia drive over 25% of ChatGPT's US citations per 5WPR's 2026 research. The share moves over time, but Reddit's position at or near the top is consistent. The model treats real user discussion as a stronger witness than company-owned pages.
Where does Google AI Overviews get its information?
Mostly from pages that already rank in Google's organic top 10, which makes classic SEO still relevant. AIOSEO found 52% of AI Overview sources rank in the top 10. Within social discussion specifically, Reddit makes up about 44% of the social citations per the TechEdge AI 2026 study, so ranking organically and being present in relevant Reddit threads feeds both halves at once.
Does ChatGPT cite Wikipedia?
Yes. Wikipedia is one of ChatGPT's most-leaned-on sources for baseline factual context, and together with Reddit it accounts for over 25% of ChatGPT's US citations. Wikipedia supplies the neutral facts while Reddit supplies the lived comparison and opinion. Both sit well above most news and editorial brands in citation share.
How does Perplexity choose its sources?
Perplexity retrieves live for each query, cites more sources than other engines, and weights freshness very heavily. Reddit accounts for about 24% of its citations per the TechEdge AI 2026 study. Because it favours recent, well-structured pages, content that directly answers the exact question can surface within days. We go deeper on this in how to get cited by Perplexity, ChatGPT and AI Overviews.
Where does Grok get its information?
Grok learns primarily from X, the platform it runs inside, so the volume and recency of posts about a topic on X shape its answers more than for any other engine. A brand that is actively and credibly discussed on X gives Grok a real body of signal. A brand that barely appears there leaves Grok guessing.
Can I influence what ChatGPT says about my brand?
Yes, by being present in the sources it pulls from rather than only on your own site. That means earned discussion in the high-trust places models cite, described consistently across several of them, kept fresh over time. You cannot edit the model directly, but you can change the corpus it reads. Our Reddit presence work is built around exactly that.
Why do AI answers about my company change?
Because the retrieval layer re-runs and the source mix shifts. A parameter change upstream moved ChatGPT's Reddit share from about 60% to 10% in six weeks once, and answers move with it. Fresher pages also displace older ones over time, since AI cites content about 25.7% fresher than classic search. Stable answers come from a consistent, maintained footprint across several trusted sources, which is the gap GEO dashboards measure but do not close.
The companies that win the AI answer are the ones present where the model reads, described the same way across enough trusted sources that it states them as fact. That presence takes time and consistency to build, and it compounds once it exists.
Want a citation snapshot for your top 10 buyer queries? Run a 20-minute visibility audit with us. We will pull what ChatGPT, Perplexity and Google AI Overviews say about you today, show you which sources are driving it, and map where the gaps are. Then we earn you a presence in the threads those engines actually cite.